理解Node.js其中最重要的概念之一是处理多连接和用户回调的并发模型(concurrency model)。这也是作为Node.js天生非阻塞的特性。
介绍
在Node,这个模型基于事件模型libuv,就像Ruby的Event Machine,或者Python的Twisted。在Node,这个事件模型通过被称为Event Loop的东西所组织。
慢的I/O操作被事件和回调所处理,因此它们不会在运行时阻塞主单线程执行。
Node中一切都是依靠这个概念,因此完全理解它及其重要。
什么是I/O?
I/O是input/output的缩写,但是到底是什么意思?
I/O被用来标记CPU中的一个进程和CPU外的任何东西之间的一种通信。包括内存,硬盘,网络,甚至其他进程。这个进程通过信号或者消息与其他外部的东西进行通信。当它们这个进程接受时,这些信号就是输入,当被这个进程发出去的时候,就是输出。术语I/O被过度使用了,因为原始地,几乎每个发生在电脑内外的操作都是一个I/O操作。但是在Node的架构内,术语I/O被用来指代访问硬盘和网络资源,这些都是所有操作中耗时最多的操作。针对计算机程序中最大的浪费来自等待这些I/O操作完成的不争的事实,Node的事件循环(Event Loop)应运而生。我们有很多方法来处理来自慢操作的请求。
我们可以同步地处理,这是最简单的方式,但是也是最糟糕的因为一个请求阻塞其他的请求。
我们可以从OS中fork一个新的进程来处理每个请求,但是面临大量请求的时候扩展性也不太可能很好。
处理这些请求最流行的方式是线程。我们可以开启一个新的线程来处理每个请求。但是线程间开始访问共享资源时线程的程序会变得相当复杂。
需要流行的库和框架使用线程。例如,Apache是多线程的,通常为每个请求创建一个线程。另一方面,它主要的替代品,Nginx是单线程的,就像Node,消除了由多线程带来的超载并且针对共享资源简化了代码。
单线程的框架比如Node,使用了事件循环来处理慢速的I/O操作请求,不会阻塞主线程运行时。这是Node中最重要的概念,那么事件循环到底是怎么工作的?
事件循环(Event Loop)
最简单可以用一行来定义事件循环:
The entity that handles external events and converts them into callback invocations
处理外部事件的实体,把它们转为回调调用
我们来看另一个定义:
A loop that picks events from the event quene and pushes their callbacks to the call stack
从事件队列中拿事件并且把这个事件对应的回调函数推到调用栈的循环
在没有首先理解要处理的数据结构之前很难理解事件循环
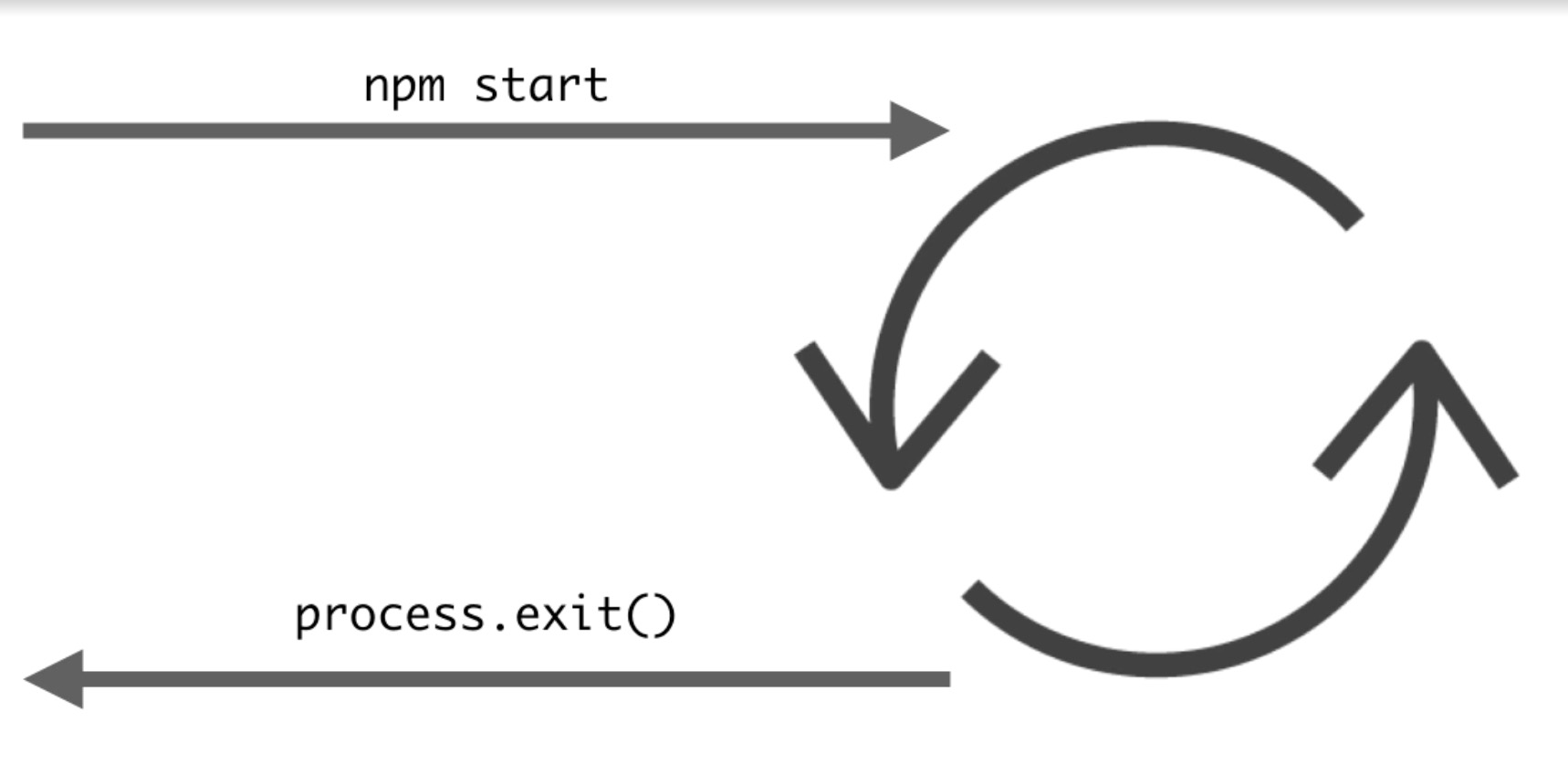
事件循环第一个要理解的是,当执行一个脚本的时候,Node自动运行,所以我们不需要手动的运行事件循环。事件循环使得异步回调程序风格成为可能。如果没有回调的时候,Node将退出事件循环。事件循环也在浏览器中有所表现,和Node很像。
为了理解事件循环,我们需要理解列表中所有的成员,我们需要理解它们是如何交互的。
V8有一块区域叫做栈,下一个模块中要详细说明。还有一块区域叫堆,堆很简单,就是内存中存储的变量所在地。基本上就是VM给不同任务分配的内存。例如,当我们调用一个函数时,堆中的一块区域被分配作为这个函数的局部作用域。堆和栈都是 运行时引擎 的一部分,不是Node本身。
Node围绕OS操作增加了一些API,比如timers,emitters,wrappers。也提供了事件队列和使用了libuv库的事件循环。事件循环,就像名字所阐述的,是一个简单的循环,工作在事件队列和调用栈之间。
下来说明其他实体概念来更好的理解事件循环。
调用栈
V8调用栈简单说就是一系列函数。栈是FILO的数据结构,可以弹出栈的顶层元素是我们最后推进栈的元素。在V8调用栈,这些元素是函数,因为Javascript是单线程的。只有一个栈,一次只能做一件事情,如果栈正在执行什么东西,在那个单线程中其他事情不会发生。当我们调用互相调用的多个函数,自然就形成了一个栈,然后我们回溯函数调用直到第一个调用。还记得如果不用递归表达式要实现可递归的东西你需要使用一个栈吗?那是因为一个正常的递归函数不管怎样都要使用一个栈。
让我们浏览一个简单的例子来阐述当我们调用函数时,栈中发生了什么
|
|
我们假设这些函数由一个立即调用函数表达式包裹。当我们运行这个代码,V8使用栈来记录程序正在执行的位置。每次我们进入一个程序,它被推入栈中,每次从函数中返回时,它被弹出栈。就是这么简单,所以我们以IIFE调用开始,也就是一个匿名函数。这个IIFE函数定义了其他函数,但是仅仅执行printDouble。printDouble被推入栈,printDouble调用double,因此我们把double推入栈,double调用add,我们把add推入栈,直到现在,我们仍旧执行所有的函数。我们还没有返回它们中的任何一个。当我们从add中返回时,我们把add弹出栈。然后我们从double中返回,把double弹出栈。现在,继续在printDouble中执行,我们进入了一个新的函数调用,console.log,因为它没有调用其他函数,立即被推到栈中。然后我们从printDouble中返回,最终匿名函数也从栈中弹出。
注意每次一个函数是如何被加入进栈的,在同一级别变量和局部变量也被加进去了。你有时会听到术语栈框架或者堆栈结构,指的是函数,它的参数和局部变量。我想当确定你之前见过调用栈,不是在Node里而是在浏览器中。每次你得到一个错误,控制台将会展示调用栈。
如果一个函数没有退出条件递归调用自身你觉得会发生什么?相当于一个无限循环,但是是在栈里面。我们将一直把同一个函数推入栈,直到达到V8栈大小,V8将打印出这条错误:
处理慢操作
只要在栈中处理的操作快一些,单线程那就没有问题。但是当我们开始着手处理慢操作的时候,我们只有一个线程的事实变成一个问题。因为这些慢操作将阻塞执行。我将用一个例子来模拟。
|
|
例子中,次数很多的循环语句就是一个阻塞操作。这里slowAdd函数将花费几秒的时间来完成,依赖于具体的硬件。那么当我们进入到一个像slowAdd这样的阻塞的函数中调用栈发生了什么?
同样的,第一次调用,匿名函数进栈,slowAdd(3,3)进栈。然后等待V8完成没用的阻塞循环并且从slowAdd(3,3)中返回并且同时弹出栈。然后进入slowAdd(4,4),并且等待,完成,返回,弹出。对于slowAdd(5,5)是同样的步骤。然后进入console.log
行,这个很快因此无阻塞,因此入栈,弹栈,入栈,弹栈,入栈,弹栈。最后匿名函数弹出栈。
当Node等待每个slowAdd的时候,它什么也做不了。这就是阻塞式程序,Node的事件循环存在的意义就是为了避免这种程序。
回调实际如何工作
我们都知道Node API围绕回调设计。我们把一个函数作为参数传递给另一个函数。这些参数函数迟点会被执行。
例如,如果我们改变我们的slowAdd函数,把它放到setTimeout中
|
|
setTimeout中的第一个参数就是回调函数。我们看看这次调用栈发生了什么。匿名函数入栈,首次调用的slowAdd(3,3)入栈,slowAdd调用了setTimeout,setTimeout入栈,因为setTimeout没有调用其他函数,但是有一个函数参数,它立即被弹出栈,所以slowAdd(3,3)执行结束。然后继续,slowAdd(4,4)入栈和第一个过程一样,最后都弹出栈。但是不知怎的,console.log(6)入栈然后执行,之后,console.log(8)入栈并执行。
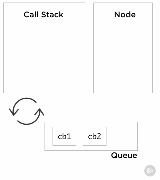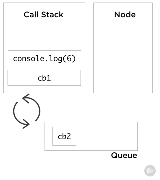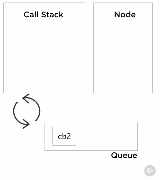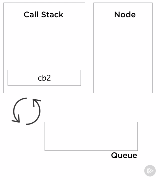
要理解最后两个调用出现在调用栈。我们得理解像setTimeout这样的API调用不是V8的一部分,是由Node本身提供的,就像浏览器会提供这个一样,是很重要的。与事件循环异步地工作看起来很奇怪,这也是为什么它在调用栈中表现得有一点奇怪。我们再谈谈事件队列。有时候称为消息队列或者回调队列。简单地列出了要被处理的事物,让我们称这些事物为事件。当我们在队列中存储一个事件,就存储了一个与之对应的函数。这个函数就是我们知道的回调函数。刚才说setTimeout是Node的一部分,当调用setTimeout的时候,Node调用timer来计时,时间到的时候就将一个回调放到事件队列中,队列是FIFO的数据结构。调用该回调函数将把它推到栈中。
事件循环做的事情相当简单。就是监视栈和事件队列。当栈是空的,队列不空时(队列中有等待被运行的事件)。它将按顺序从队列中让事件出队列,然后把对应的回调函数推入栈。它称为事件循环,因为它循环这个简单的逻辑直到事件队列为空为止。栈和事件队列都为空的时候,Node会退出进程。所有的API背后的工作原理都是它。一些进程将异步处理一定的I/O,持续追踪一个回调,当它结束时,它将把回调放在事件队列中排队。时刻保持清醒,任何慢的代码在栈中执行将阻塞事件循环。同样地,如果我们不注意事件队列中事件的数量,我们将压垮队列,使得事件循环和调用栈都忙碌。作为一个Node开发者,对于阻塞和非阻塞代码还有很多重要的东西要理解。
setImmediate和process.nextTick
当timer延迟时间为0毫秒的时候会发生什么?差不多是一样的事情。
前面的步骤类似。因为这个循环,timers在0毫秒之后没有真的在执行,还是在我们处理完栈之后。所以如果在栈中有一个慢操作,这些timers就得等了。在一个timer中定义的延迟并不是一个保证的时间来执行,但是确实是执行的最小的时,timer将在这个延迟的最小值之后执行。
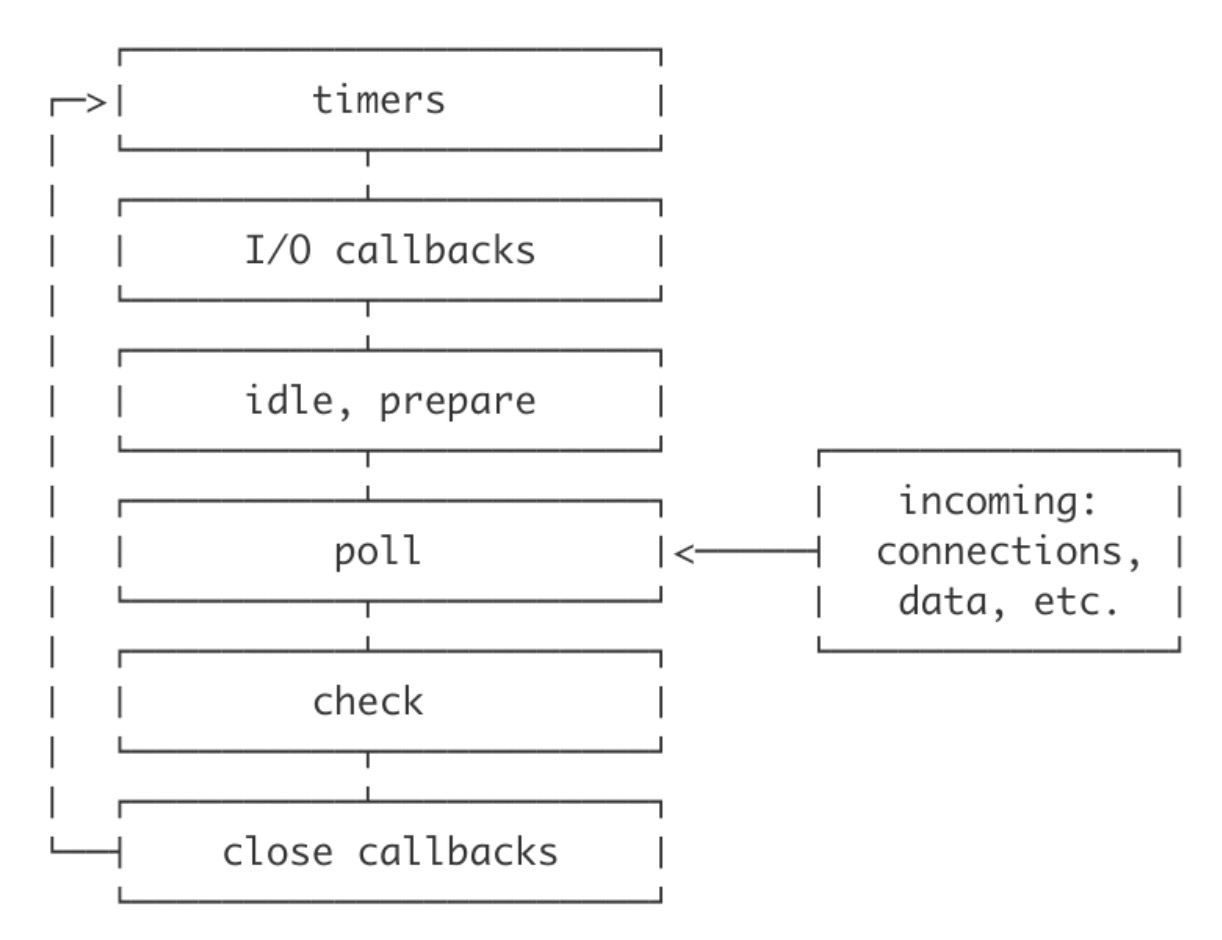
Node的事件循环有多个阶段,timers运行在其中一个,然而大部分的I/O操作运行在其他阶段。Node有一个特殊的timer——setImmediate,运行在事件循环的一个单独的阶段。
几乎等同于0ms timer,除了其他一些情况,setImmediate将实际上优先于setTimeout的0ms
|
|
当你想某个东西在事件循环的下一个tick被执行,最好用setImmediate
Node中还有一个API,叫做process.nextTick和setImmediate看起来一样,但是Node在下一次循环不会执行它的回调,因此这个名字令人误解,但也没法去改。
process.nextTick技术上来说不是循环的一部分。并且它不关心循环的阶段。在当前操作完成之后,Node处理由nextTick注册的回调,在事件循环继续之前。这个既有用,又危险,要小心对待,尤其在递归使用process.nextTick的时候。
使用nextTick一个好的例子是与一个标准函数做对比
|
|