Node.js 流是出了名的难用,难理解。近几年,工程师创造了大量与流有关的包,目的是想让我们更简单的使用流。但是这篇文章中,将关注于原生的Node.js流API。
到底什么是流?
流是一次性拿不到的数据的集合,流不需要适应内存的大小。这个特性使流在处理大量的数据或一次性来自其他地方一大块数据的时候相当强大。
然而,流不仅仅是用来处理大数据的,在代码层面具有可组合性。就像我们能够使用很多很小的Linux命令来组合成一个功能更强大的命令一样,在Node中用流也能达到一样的效果。
|
|
|
|
Node中许多内置的模块继承了流接口:
| Readable Streams | Writable Streams |
|---|---|
| HTTP responses,on the client | HTTP requests,on the client |
| HTTP requests,on the server | HTTP responses,on the server |
| fs read streams | fs write streams |
| zilb streams | zlib streams |
| crypto streams | crypto streams |
| TCP sockets | TCP sockets |
| child process stdout and stderr | child process stdin |
| process.stdin | process.stdout and stderr |
上面的这个列表包含了一些可读流和可写流的原生Node.js对象。这些对象中有的即时可读流,又是可写流,像TCP sockets和crypto streams。
注意这些对象也是紧密相关的。当一个HTTP response在客户端是一个可读流的时候,在服务端就是一个可写流。这是因为在HTTP里,我们通常从一个对象(http.IncomingMessage)中读,写入另一个对象(http.ServerResponse)。
当谈及child process的时候也要留神stdio流(stdin,stdout,stderr)有相反的流类型。
一个流例子
理论很伟大,但是不能100%让人信服。我们一起来看一个例子,在内存消费的场景中,流能够带来哪些不同
让我们先创建一个大文件
|
|
看看我是怎么创建那个大文件的,一个可写流!
使用流接口,fs模块可以被用来从一个文件中读或写入这个文件。在上面的例子中,我们在一百万次的循环中用一个可写流向文件big.file写入字符串。
下面是一个简单的Node服务器,用来专门存放这个big.file
|
|
当服务器收到一个请求,它将使用同步方法fs.readFile来提供大文件。但是,不像是我们阻塞了循环或者其他东西,什么都正常,对吗?对吗?
好了,我们来看看当我们运行这个服务器的时候到底发生了什么,访问该服务并且监视内存。
当我运行服务器的时候,开始是一个正常量的内存值,8.7MB: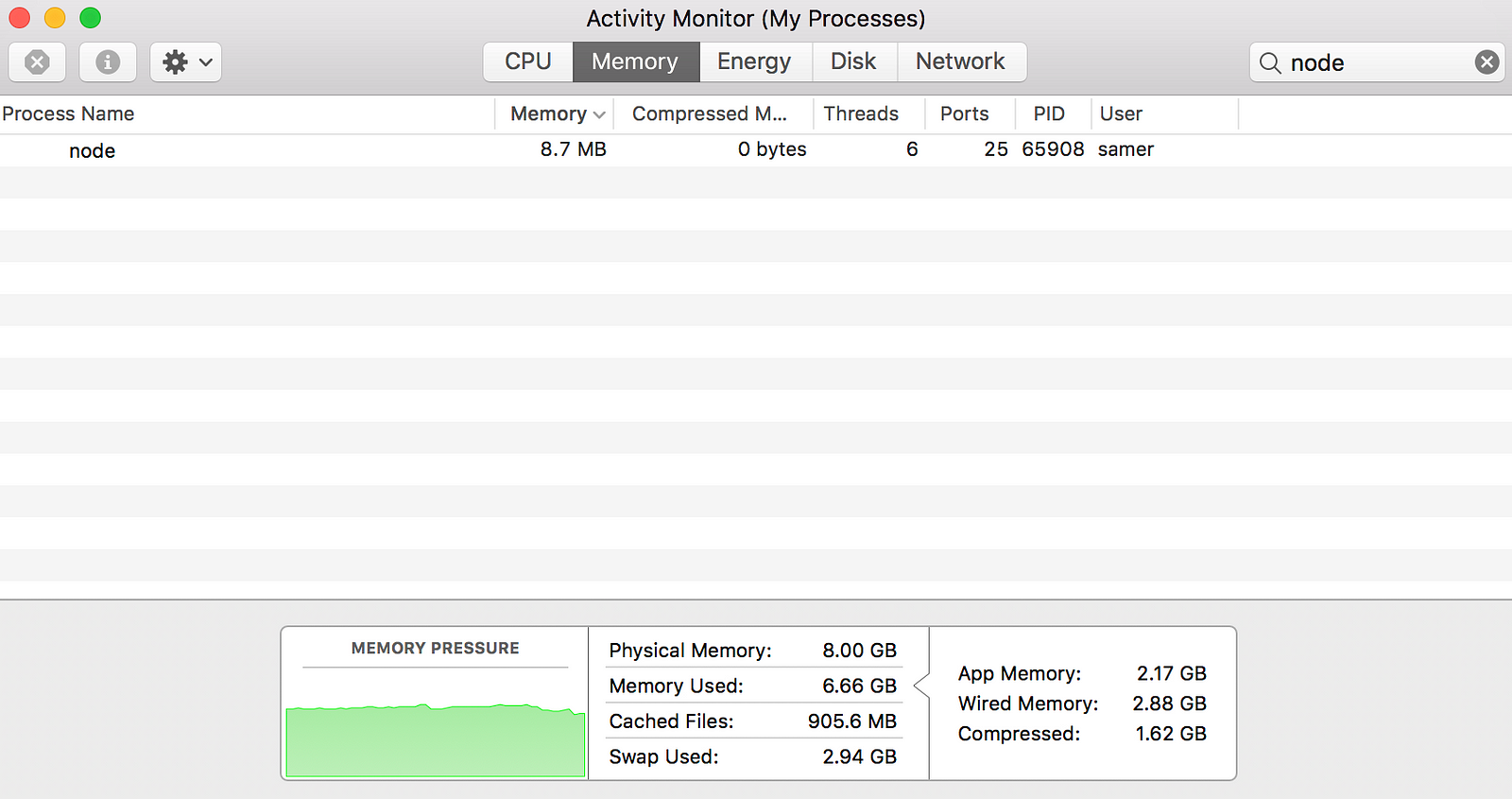
然后我连接到服务器,注意内存消耗了多少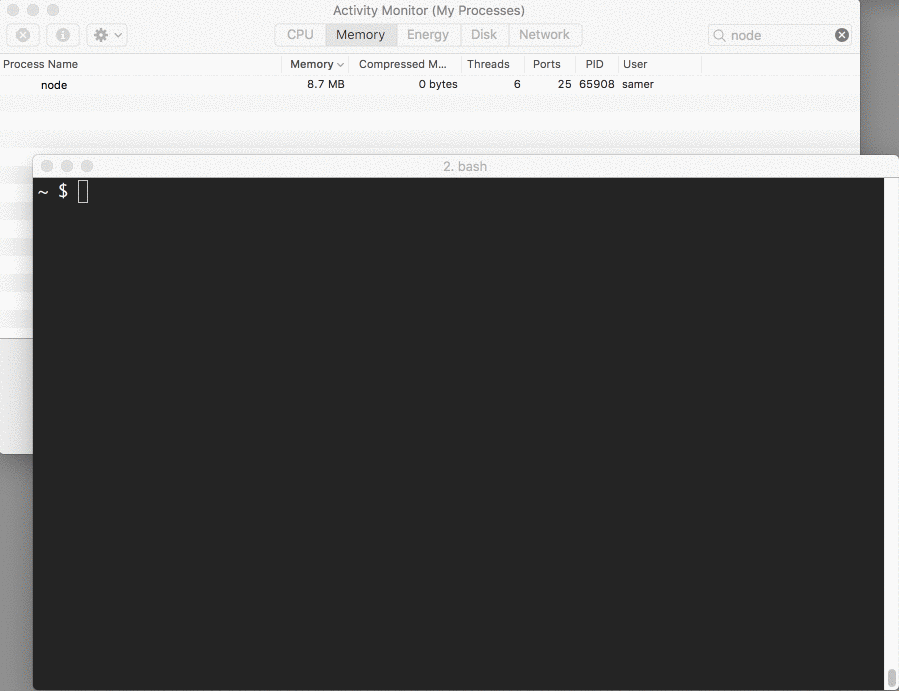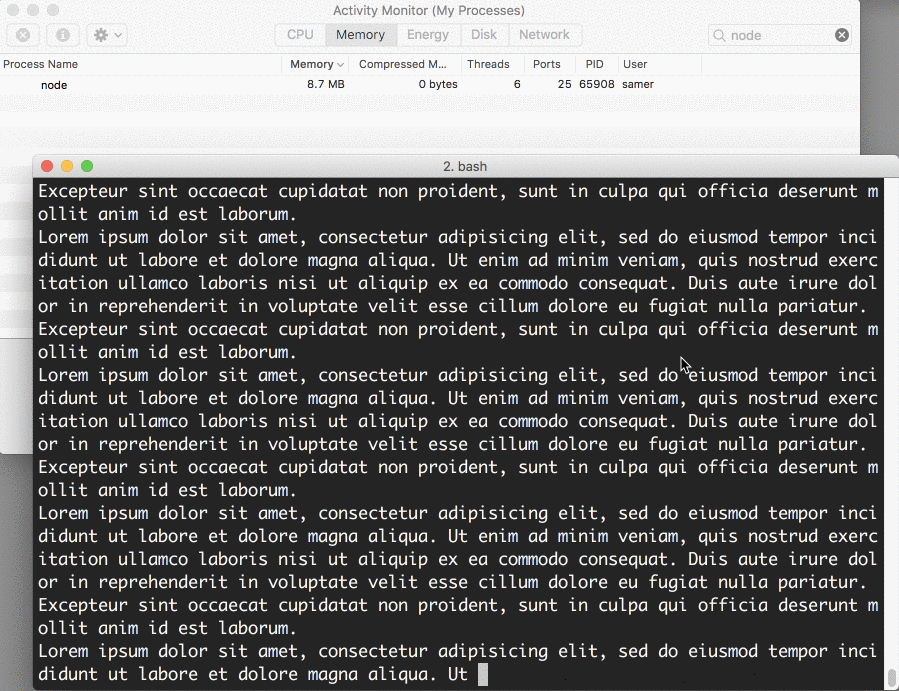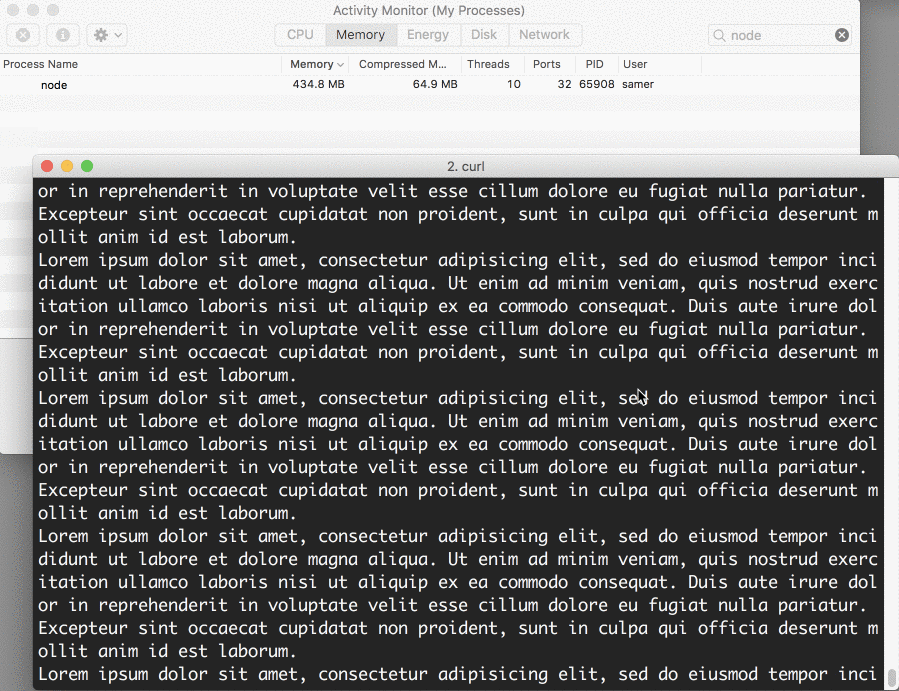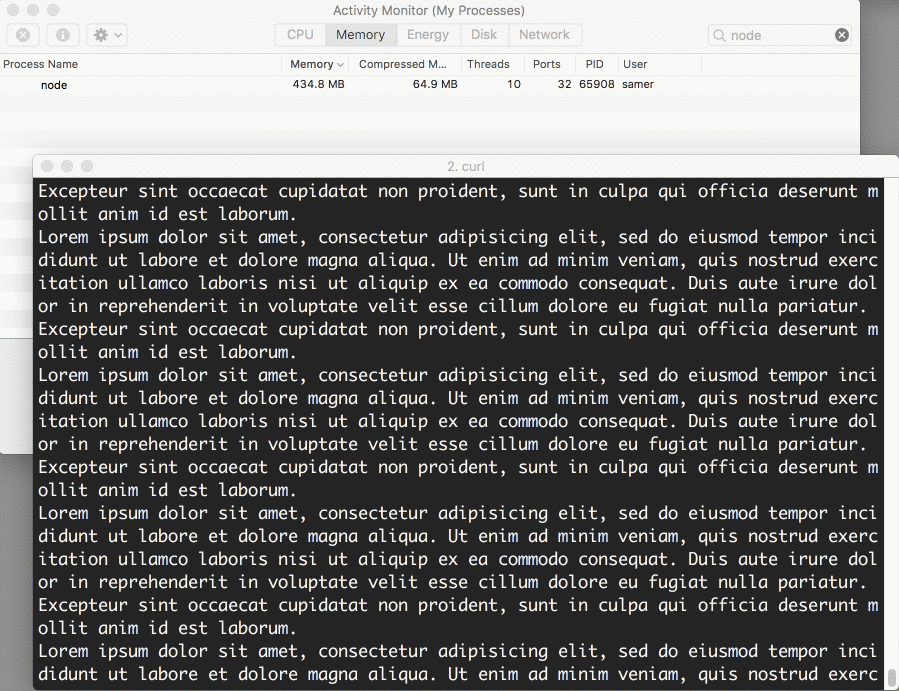
哇~内存飙到了434.8MB
我们基本上是在写入响应对象之前把整个big.file放到了内存中,这个非常不高效。
HTTP响应对象(上面的res)也是一个可写流。这个意味着如果我们有代表big.file内容的可读流,我们就能将这两个像管道一样互相连接起来,可以达到和刚才一样的效果却几乎不需要额外的400+MB的内存消耗。
使用createReadStream方法,我们能够使用Node的fs模块为任何文件创建一个可读流。我们可以把它连接到响应对象上。
|
|
现在当我们再连接到这个服务器的时候,奇迹发生了(看内存消耗)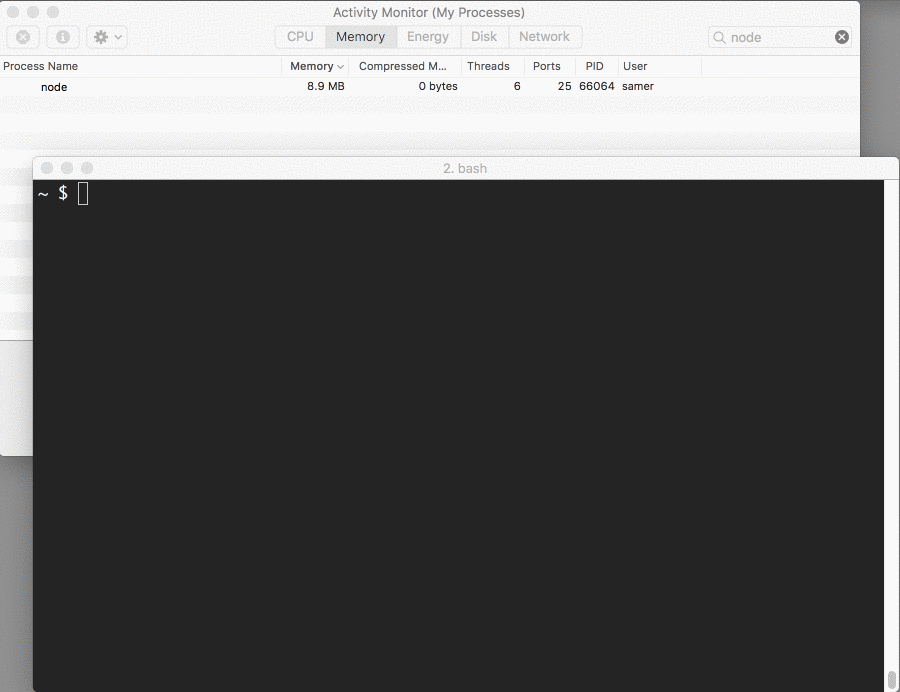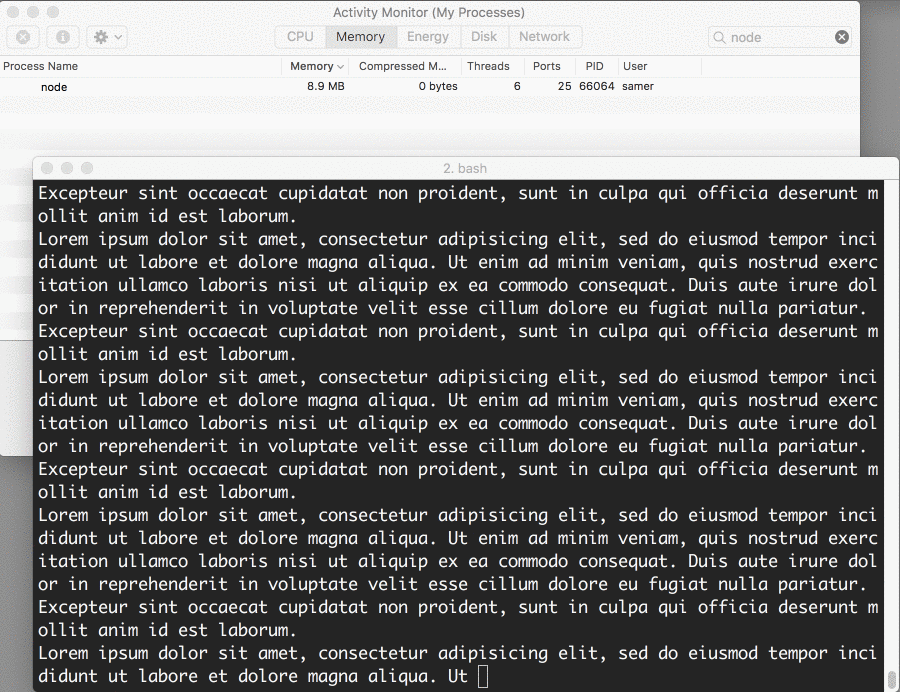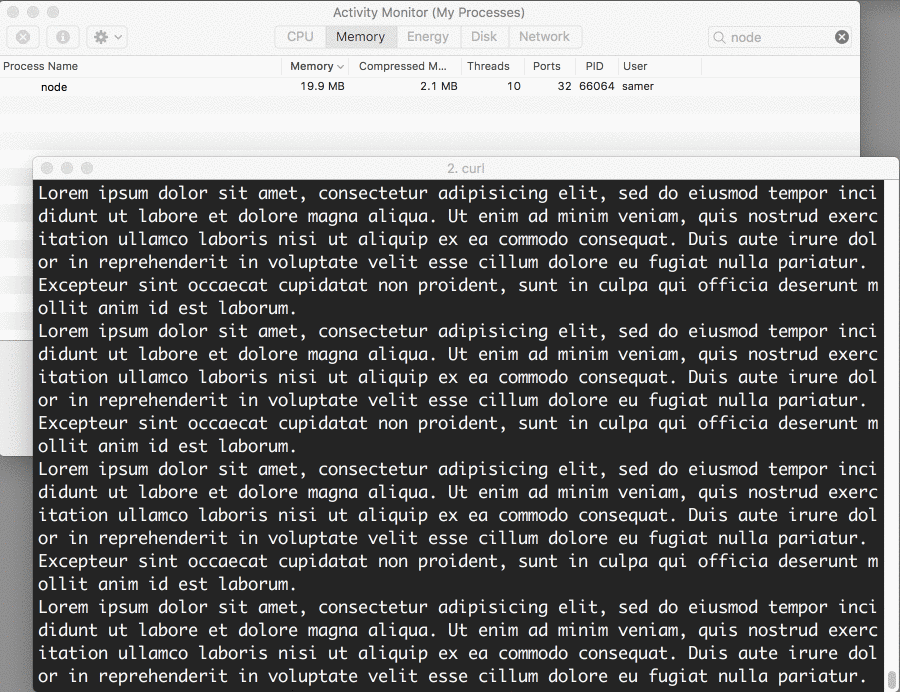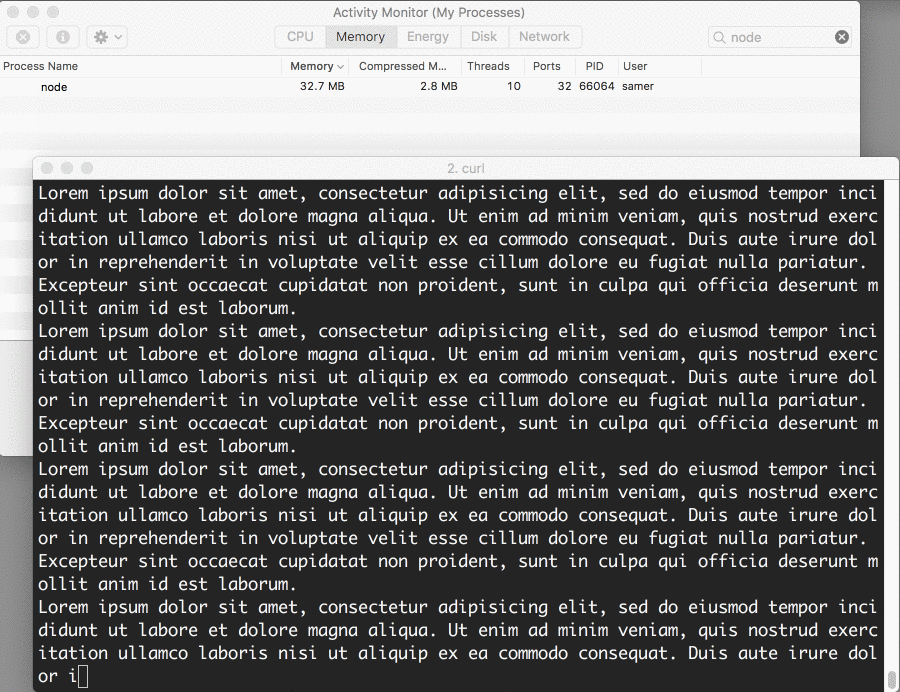
发生了什么?
当客户端请求大文件的时候,我们一次使用流传输一块数据,意思是我们不用一次全部缓存在内存中。内存增长到大概25MB,这就是流的威力。
你可以把这个例子运用到它的极限,用五百万循环重新生成big.file,文件大小大概有2GB,这个实际上比Node中默认的缓存限度要大。
如果你尝试使用fs.readFile来服务这个文件是行不通的,但是使用fs.createReadStream,对访问者流传输2GB的数据是没问题的。最好的一点是,进程的内存使用和开始几乎是一样的。
准备好学习streams了吗?
Streams 101
Node.js中一共有四种基本的流类型:Readable,Writable,Duplex和Transform streams
- 一个可读流是对数据源的抽象,比如
fs.createReadStream方法 - 一个可写流是数据要被写入目的地的一个抽象,比如
fs.createWriteStream方法 - 一个双重流既是可读流又是可写流,比如TCP socket
- 一个转化流是一个在写和读数据的时候能够修改或者转化的双重流。比如
zlib.createGzip流使用gzip来压缩数据。你可以把转化流想象成一个函数,输入是可写流,输出是可读流。你或许听到过转化流被称为“through streams”。

所有的流都是EventEmitter的实例,他们能够发出能够读和写数据的事件。然而,我们能够用一种更简单方法——pipe方法来消耗流数据。
pipe方法
下面是一行你需要记住的神奇的一行代码
|
|
在这行简单的代码中,我们连接了可读流(数据源)作为可写流(目的地)的输入,源是可读流并且目的地是可写流。当然了,也可以是双重流/转化流。实际上,如果我们连接到一个双重流,我们可以像在Linux中做的那样链式调用。
|
|
pipe方法返回目的流,所以我们能够链式调用,对于流a(可读), b和c(双重),和d(可写),我们能够
|
|
pipe方法是最简单的方法来消费流。通常推荐使用pipe方法或者使用事件来消费流,但是避免混合这两者。一般地,你使用了pipe就不必使用事件了,但是如果你需要用更自定义的方式消费流,事件就要派上用场了。
流事件
除了从可读流中读数据并且写入可写目的流中,pipe方法自动地管理了一些东西。例如,处理错误,文件末尾,一个流比另一个流慢或快。
然而,流也能直接通过事件来被消费。下面是一个简单的例子,等同于用pipe方法做的读和写数据。
|
|
下面是可读流和可写流中一些重要的事件和函数
这些事件和函数在某种程度上是有关系的因为他们总是被一起使用。

可读流中最重要的事件有:
data事件,只要流传递给一块数据给消费者就会触发end事件,当流中没有数据要消费时触发
可写流中最重要的事件有:
drain事件,这是一个信号,代表可写流能够接受更多的数据finish事件,当所有数据被刷新到底层系统时触发
事件和函数可以结合来创建一个自定义和优化的流。要消费一个可读流,我们能够使用pipe/unpipe方法,或者read/unshift/resume方法。要消费一个可写流,我们使它作为pipe/unpipe的目的流,或仅仅用write方法来把数据写入并且当我们做完时,调用end方法
可读流暂停(paused)和流动(flowing)模式
可读流有两个主要的模式能够影响我们消费它们:
- 它们或者在暂停模式
- 要么在流动模式
这些方法有时称为 pull 和 push 模式。
所有的可读流开始时默认是暂停模式,但是它们能够在需要时轻易地转换成流动模式并且返回到暂停模式。有时,转换会自动发生。
当一个可读流在暂停模式时,我们能够按需使用read()方法来从流中读,然而,对于流动模式的可读流,数据是持续流动的,我们不得不监听事件来消费它。
在流动模式下,如果没有消费者来处理数据实际上就丢失了。这也是为什么,我们有一个流动模式的可读流需要一个data事件处理器。实际上,仅仅增加一个data事件处理器将一个暂停模式的流转换成了流动模式的流,移除data事件处理器就会将流转回暂停模式。更老版本的Node流的接口大部分做了向后兼容。
要手动在两种流模式间转换,你需要使用resume()和pause()方法。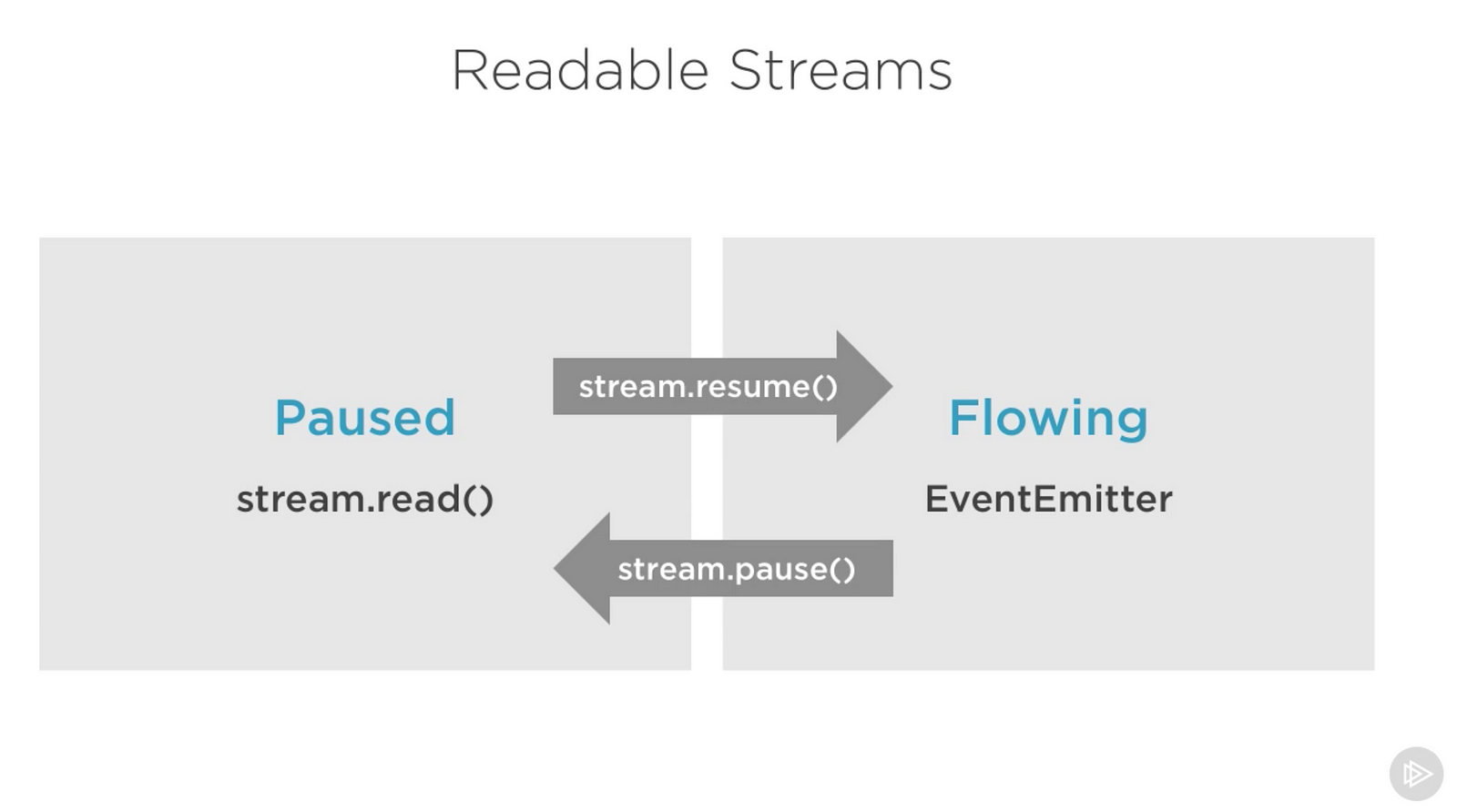
当使用pipe方法消费可读流时,我们不必担心这些模式,因为pipe自动管理它们。
实现流
当谈论Node.js中的流时,主要有两个不同的任务:
- 实现流的任务
- 消费流的任务
直到现在我们仅仅在讨论消费流,让我们来实现它!
实现可写流
要实现一个可写流,我们需要使用流模块的Writable构造器
|
|
我们可以通过许多方法来实现一个可写流。我们能够例如继承Writable构造器
|
|
然而,我更喜欢简单的构造器方法。我们只需要从Writable构造器中新建一个对象,并且传递一些参数。它唯一需要的参数是一个write函数,这个函数被用来给资源发送数据。
|
|
write方法接受三个参数
- chunk通常是一个缓存,除非我们配置了流
- encoding参数在这个例子里是必要的,但是通常我们会忽略它
- callback是一个函数,我们需要在处理完数据chunk之后调用,它是写方法成功还是失败的信号。如果失败了,会用一个error对象来调用callback
在outStream,我们仅仅将chunk作为字符串打印并且在没有错误的情况下调用回调函数。这是一个非常简单可能不是很好用的 回声(echo)流,它会对接受到一切东西回显出来。
为了消费这个流,我们简单地使用了process.stdin,这是一个可读流。因此我们能够用管道将process.stdin连接到outStream。
当我们运行上面的代码时,任何我们输入进process.stdin的东西都会被使用了outStream的打印函数回显出来。
要实现的话,这不是一个很有用的流。因为它实际上已经实现了并且是内置的。他非常等同于process.stdout。我们可以仅仅连通stdin和stdout,我们就能够得到同样的回显效果,代码如下
|
|
实现可读流
要实现可读流,我们需要Readable接口并且根据这个接口构造对象
|
|
这是一种实现可读流的简单方法。我们想要消费者来消费的话,直接用push方法就好了
|
|
当我们push一个null对象时,意味着我们想告诉流不需要数据了。
为了消费这个简单的可读流,我们简单地把它连接到可写流process.stdout。
当我们运行上面的代码时,我们将从inStream中读到所有的数据,并且回显到标准输出上。非常简单,但不是很高效。
在把它连接到process.stdout之前,我们基本上把所有的数据推到了流里。更好的方法是当消费者要的时候,按需推数据。为了达到这个要求,我们要在可读流配置中实现read()方法:
|
|
当读方法在可读流中被调用,代码实现部分能够将部分的数据推到队列中。例如,我们一次能够推一个数据,从字符码65(A)开始,每推一次增加一个数字。
|
|
现在我们将上面read中的代码放入到一个计时器中,并且修改执行顺序。可以实现一个很cool的效果,你们可以自己动手实现一下,试试不同的延迟时间。
|
|
双重流和转化流
有了双重流,我们可以用同一个对象实现可读流可写流,就像我们从两个接口中继承得一样。
|
|
很重要的一点要知道,双重流中的读和写没有半毛线关系,他们只是结合在了一个对象中,他们是独立的。
转换流是更有意思的双重流,因为他的输出是从输入中计算得来的。无需实现read或者write方法,仅仅需要一个transform方法就好了,
|
|
让我们看一个更实用的例子,zlib的createGzip()函数。我们同时巧妙的结合了事件
|
|
如果想在gzip之前加密文件,我们只需要再接一个转换流
|
|
下面的代码是对加密压缩文件的解密和解压缩。
|
|