单线程、无阻塞性能相当好,但是一个CPU中的一个进程还是没法应对更多的负载。不管你使用多么强大的服务器,单线程总是有限度的。
扩展Node.js应用程序
Node运行在单线程的事实并不意味着我们不能利用多进程,当然,多个机器也是可以的。使用多进程是增大Node.js应用规模唯一的方法。Node.js被设计用于构建多节点的分布式应用。在应用程序生命周期中,可扩展性不是一开始就要思考的东西。
负载是我们扩展我们应用最重要的原因,但不是唯一原因。我们扩展程序也为了达到增加可实用性,容错性的目的。
在谈论Node.js的扩展性之前,我们来讲一下可扩展性的不同策略,在扩展一个应用的时候主要有三件事情。
(Cloning)扩展一个应用最简单的是多次克隆它,用每个克隆的实例来减轻负载。会消耗很多开发时间但很高效。本文着重说这个方法。
(Decomposing)我们也会通过分解来扩展应用,基于函数性和服务性。意味着不同的代码库有多个不同的应用,有时它们也会有专用的数据库和UI。这个策略和一个术语microservice关联,micro指示这些服务应该尽可能小。但是实际情况下服务的大小没那么重要,服务间的强制松散耦合和高内聚才是更重要的。这个策略的实现经常不是很简单,可能会造成意料不到的问题。但是优势也是很明显的。
(Splitting)第三个策略是把这些应用拆分成多个实例,每个实例负责应用数据的一部分。这个策略在数据库操作中经常被叫做水平分割(horizontal partitioning),或者分片(sharding)。数据划分在每个操作之前需要检查步骤来决定应用的哪个实例来使用这些数据。例如,我们想基于国家或语言来划分我们的用户,我们需要首先检查这个信息。
成功地扩展一个应用应该最终都实现了这三种策略,Node.js使得实现变得简单。
子进程事件和标准I/O
我们可以使用child_process模块来轻易地造出一个子进程,这些子进程在一个通信系统中可以互相通信。
通过在子进程中调用任何系统命令,child_process模块使得我们可以访问操作系统函数。控制输入流,监听输出流。我们可以控制传给系统命令的参数,可以对输出做我们想做的事情。例如,将一个命令的输出连接到另一个命令,因为这些命令的所有的输入和输出都可以使用Node流。
下面用到的例子的命令都是基于Linux的,在Windows上,你需要找到替代的命令。
Node中创建一个子进程有四种方式
- spawn()
- fork()
- exec()
- execFile()
spawn方法在新进程中运行一个命令,我们可以使用它来把任何参数传递给系统命令。
spawn方法的结果是一个ChildProcess实例,并且继承自EventEmitter,意味着我们可以为子进程对象的事件注册监听器。
子进程结束的事件是end,可以接受两个参数code和signal。这是子进程退出的代码和信号变量。当子进程正常退出的时候,signal为null。
其他的事件还有disconnect、error、message、close
当父进程手动调用子进程的disconnect方法时,子进程的disconnect事件触发。
如果进程不能被spawn或者kill的时候,error事件触发。
当子进程使用process.send()来发送消息的时候,message事件触发。process.send()也是父子进程如何通信的原理。
当子进程stdio流关闭时,close事件触发。每个子进程都会有三个stdio流。child.stdin、child.stdout、child.stderr
close事件不同于exit事件,因为多个子进程或许共享同一个stdio流,并且一个子进程退出不代表流关闭。
不像在正常的进程里,在子进程中stdout/stderr是可读流,stdin是可写流。和正常流刚好相反。在流中我们也能够监听事件,最重要的是,可读流中我们可以监听data事件,当执行命令的时候,会得到命令的输出结果和遇到的错误。stdout/stderr的监听器将记录主进程的标准输出和错误。
我们给spawn通过第二个参数调用任何命令,第二个参数是一个要传给第一个参数命令的所有选项。
|
|
当遇到错误的时候,监听的stderr将会打印出错误,并且程序以特定代码退出。
子进程的stdin是一个可写流,可以使用它来给我们要执行的命令发送一些用户输入的指令。就像任何可写流一样,最简单的方法就是用pipe
|
|
我们也可以把标准输入连接到多个进程的输出,就像在Linux上做的那样
|
|
Shell命令exec()和execFile()
默认地,spawn方法不能创建一个shell来执行我们传递的命令,比起exec方法来说稍微有效率一些,因为exec会创建一个shell。exec方法主要有另一个不同之处。它缓冲了命令执行后的结果并且把所有的值传给了回调
|
|
上面的例子可以看出,将结果传给了回调中的 stdout。我们也可以看出使用 exec 的便捷性。所以当我们需要使用shell语法并且返回的结果不是很大的时候,exec 是一个好的选择。而spawn适用于结果返回的数据大的情况下,我们可以用流来处理。
我们也可以让子进程继承父进程的的stdio对象
|
|
执行上述代码之后,data事件将在process.stdout上触发,使得结果立即展现出来。如果我们想使用shell语法,并且也能利用spawn方法带给我们使用流的便捷性,我们可以使用shell选项,设置为true。和exec不同的是,仍旧不会缓冲结果。这是最棒的两个使用。
我们也可以使用其他参数,cwd来改变脚本执行的目录, env来指定在新进程中可见的环境变量。默认的是process.env。因此所有命令都能执行当前脚本。detach使子进程独立地运行在父进程中,实际的效果依赖于OS。Windows中,detached子进程有自己的console窗口,Linux中detached子进程成为进程组和session的首领。如果在detached子进程中调用unref方法,父进程将独立于子进程退出。当子进程计算量大的时候,要把它放到后台来运行这个特点极其有用。此时,stdio应该设置为ignore,因为stdio也应该独立于父进程。
如果不想用shell来执行一个文件,使用execFile方法。和exec差不多,只是不会使用shell,更高效一点。但是当使用execFile的时候io direction和file clobbing就不被支持了。在Windows中,一些文件比如.bat,.cmd不能自己执行,这也文件也不能被exec
File执行。exec或者设置了shell为true的spawn可以做到。
所有的child_process模块函数都有同步阻塞的版本,他们会等待直到子进程退出。对简化脚本任务或者其他启动程序任务来说有用,在其他情况下最好避免。
fork()函数
fork函数是spawn函数的变体。spawn和fork最大的不同是当使用fork的时候会在子进程中建立一个通信信道。因此我们可以在父子进程间使用send方法来交换信息。和EventEmitter模块做的事情很类似。
Cluster模块
cluster模块在多CPU环境上实现负载均衡。基于fork函数,允许我们和CPU数量一样多的次数fork主应用进程,然后它将在forked好的进程中把主进程的所有请求接管过来并且均衡他们。
cluster是Node中实现克隆扩展策略的模块,但是仅仅在一台机器上。因此当你有一台拥有很多资源或者可以不费吹灰之力就能添加更多的资源到这个机器而不是新的机器的大机器时,那么cluster是一个很棒的选择来实现快速的克隆扩展策略。
甚至小的机器都会有多核,或者你根本不担心你Node应用程序上的负载,不管怎样你都应该开启cluster模块来增加你服务器的可利用率和容错率。当你使用一个进程管理比如pm2的时候,简单到只需要提供一个参数就能够运行了。但是我会给你展示原生的closet模块是怎么使用的,并解释它的工作原理。
我们创建一个master进程,这个master进程fork许多工作进程并且管理他们。每个工作进程代表了我们想要扩展的应用程序的实例。所有的请求被master进程处理并且master进程来决定哪个工作进程来处理这个请求。
master进程的工作很简单,它实际上采用了round-robin算法来选择工作进程。这是所有平台上默认支持的,除了Windows。也可以被全局修改来让操作系统处理负载均衡。round-robin算法给所有进程轮流分发载荷。第一个请求被转发给第一个工作进程,第二个请求给下一个工作进程,等等。当到达最后一个的时候,算法又从头开始计算。这个是最简单最实用的负载均衡算法。然而,并不是唯一的一个。更多的特征算法允许分配优先级,选择最小的负载服务器或者反应速度最快的那一个。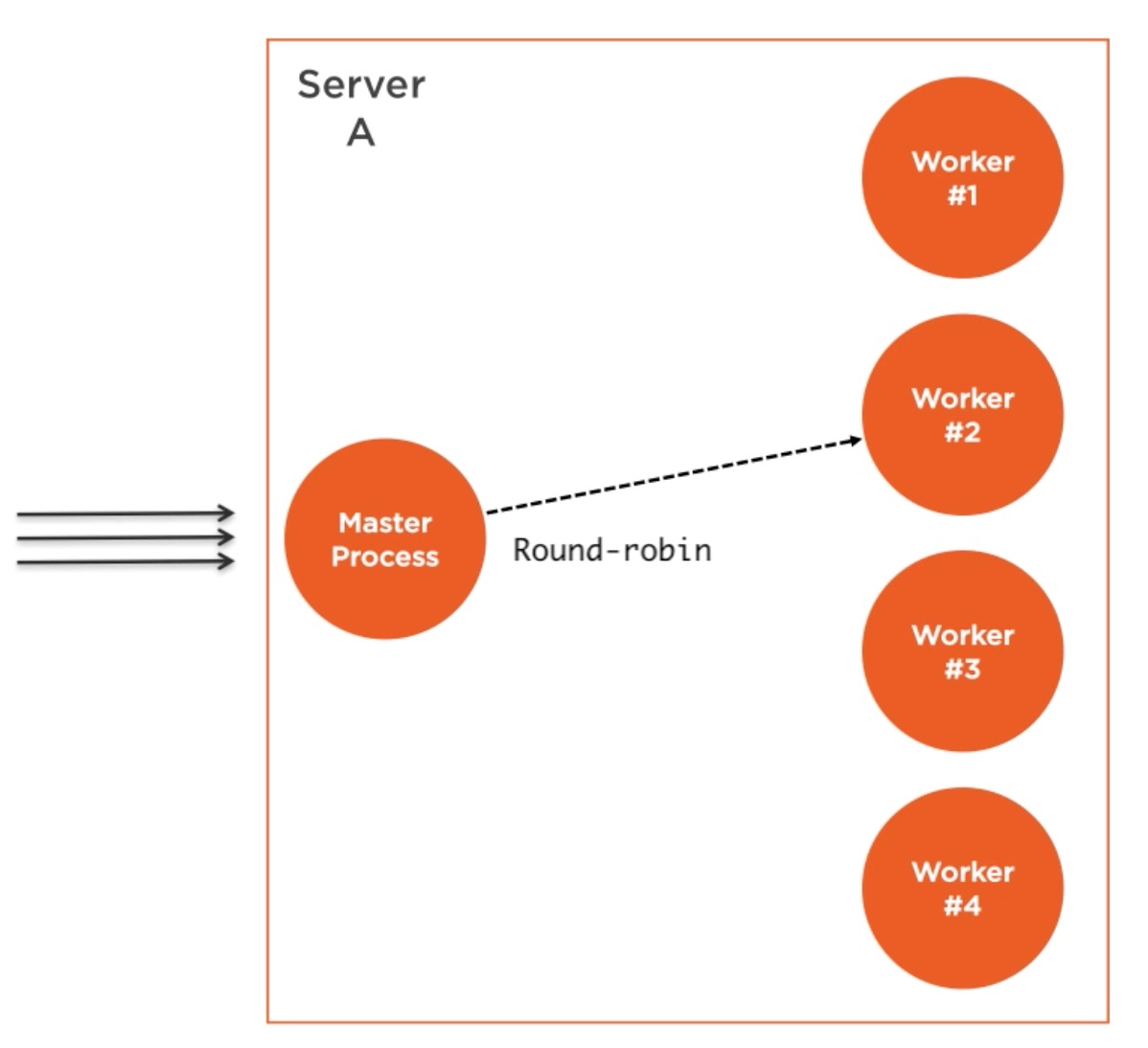
在HTTP服务器上实现负载均衡
我们将使用cluster模块来对http服务器实现克隆和复杂均衡
|
|
上面的例子是稍微修改过的简单服务器例子,来模拟响应前的CPU工作。为了验证我们创建的均衡起作用,我在HTTP响应中使用process的id来区分应用的哪一个实例在处理这个请求。
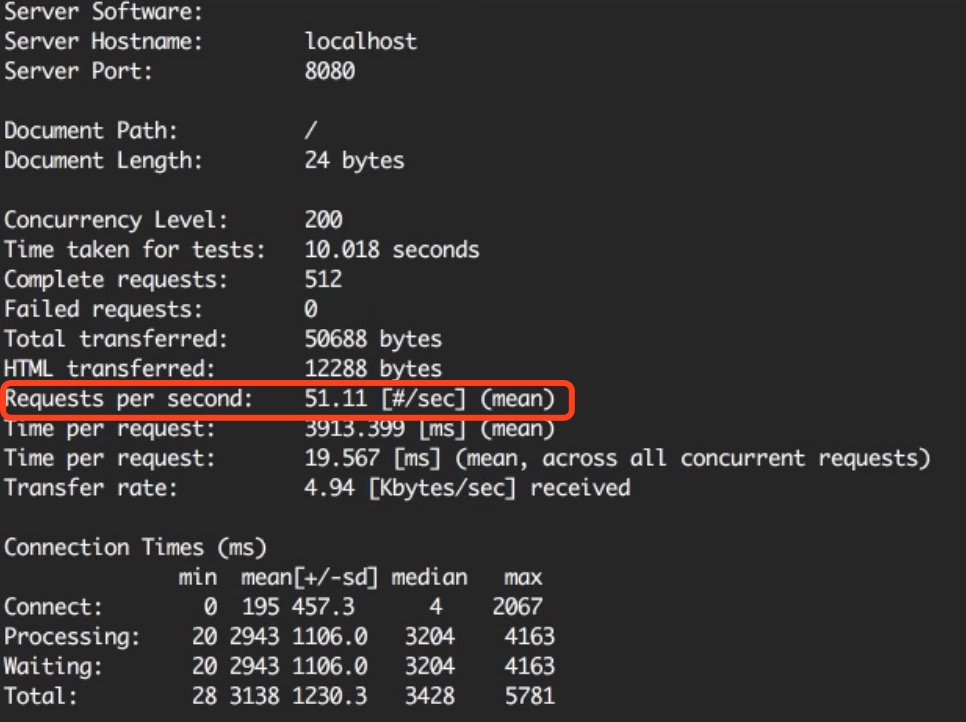
在我们创建一个cluster来克隆这个服务器变成多个工作进程之前,我们来测试一下每秒钟这个服务器能够处理多少个请求并作为基准,等着一会来对比。我将使用ApacheBench工具,得到的结果视不同的平台而定。
cluster有一个isMaster的标志,查看是否被作为master进程来加载。第一次执行这个文件的时候,我们将执行master进程,isMaster是true。这种情况下,我们可以通知master进程来根据CPU数目多少来多次fork服务器,调用cluster.fork即可。当执行这个方法后,当前的主模块cluster.js再次运行,此时isMaster为false,此时isWorker为true。当应用程序以work运行时,就开始做实际的工作了。
|
|
运行之后,可以看到开启了8个进程。要注意,这些都是完全不同的Node.js进程,每个工作进程都有它自己的事件循环和内存空间。
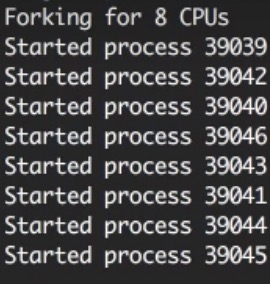
当再次在浏览器中访问时,我们就能看到不同的进程id。注意到这些进程id并不是按顺序的,这是因为cluster模块对选择下一个工作进程做了优化。但是负载确实被均衡了。使用ab命令在做一次测试。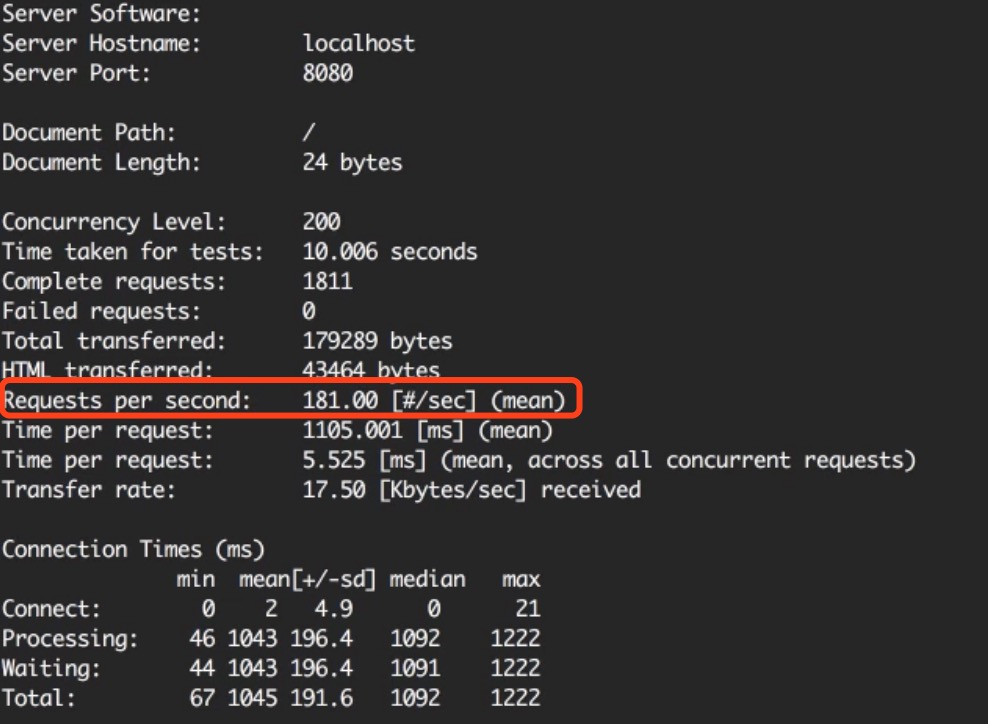
消息广播到工作线程
master进程和工作进程之间的通信很简单,因为本质上,cluster模块仅仅使用child_process.fork API,也意味着我们在master进程和工作进程之间打开了一个通信信道。
实用性和零宕机
在Node应用里运行一个单例还是多个的问题之一是当实例崩溃时,需要重启,那么这两个动作之间就会有宕机时间,即使进程是自动运行。这也暗示了一种情况,当服务器不得不重启来部署新的代码时。一个实例的时候,将会有宕机时间将会影响系统的实用性。当我们有多个实例时,系统的实用性可以通过增加几行代码轻易地提高。
为了在服务器进程模拟一个随机崩溃,可以用setTimeout随机时间之后触发process.exit。
|
|
在任意worker上执行kill或者disconnect,exitedAfterDisconnect将会被置为true。有了上面的代码,再也不用担心某个进程挂掉了,master守卫者将为我们留意这些进程。如果我们想重启所有的工作线程呢,例如当部署新代码时。
我们现在有多个实例在运行,因此不必一起重启他们,我们可以简单地一次重启一个,当一个工作线程正在重启时,允许其他的工作线程继续服务请求。实现起来也很简单。我们不想在启动时重启master进程,那么我就需要一个方法来让master进程重启worker进程。Linux系统中,我们可以监听一个USER信号,比如SIGUSR2,我们用kill命令作用在进程id,并传递那个signal表示不是要kill 掉这个进程。这种情况下,master进程不会被kill,那么我们就可以做接下来的事情了。为什么不用SIGUSR1是因为Node的debugger占用了
|
|
可以用现成的包PM2来守卫线程。
共享状态和粘性的负载均衡
花费时间能做出好东西,当我们对一个node应用进行了负载均衡,我们已经失去了一些只有在单线程上才有的特性。这个问题和我们熟知的其他语言比如线程安全很像。线程安全是关于线程间的共享的数据,在我们 这个例子中是不同worker线程间的共享的数据。
例如,cluster启动后,我们不再在内存中缓存东西,因为每个worker线程有自己的内存空间。因此如果我们在每个worker内存中缓存东西,其他worker访问不到。
如果我们需要缓存一些东西在cluster中,我们不得不使用一个独立的实体并且从所有的worker中用实体的API读或写数据。这个实体可以是一个数据库服务或如果你想使用in-memory缓存,你可以使用Redis或你可以创建一个对所有其他worker线程都能互相通信的带有read/write API,专用的Node进程。不要认为这是一个缺点,如果你还记得扩展策略的话,对你的应用缓存需求使用一个单独的实体是为扩展分解你的app的一部分。因此即使你运行在单核线程上也应这么做。
相比缓存,当你运行在cluster上时,状态性通信通常变成了一个问题。因为通信对同一个worker无法保证,在其他worker上创建一个状态性信道不是一个办法。最常见的解决方案是验证用户。
在cluster内,验证请求到达负载均衡,也就是到达某一个worker线程。例子中给了A,A现在识别用户的状态。但是当同一个用户再次请求的时候,master线程将把它分派给另一个worker,例子中是B,B中没有对用户做过认证。因此在一个即时内存中保持授权用户会话的引用不再有用。这个问题可以有多种解决方案。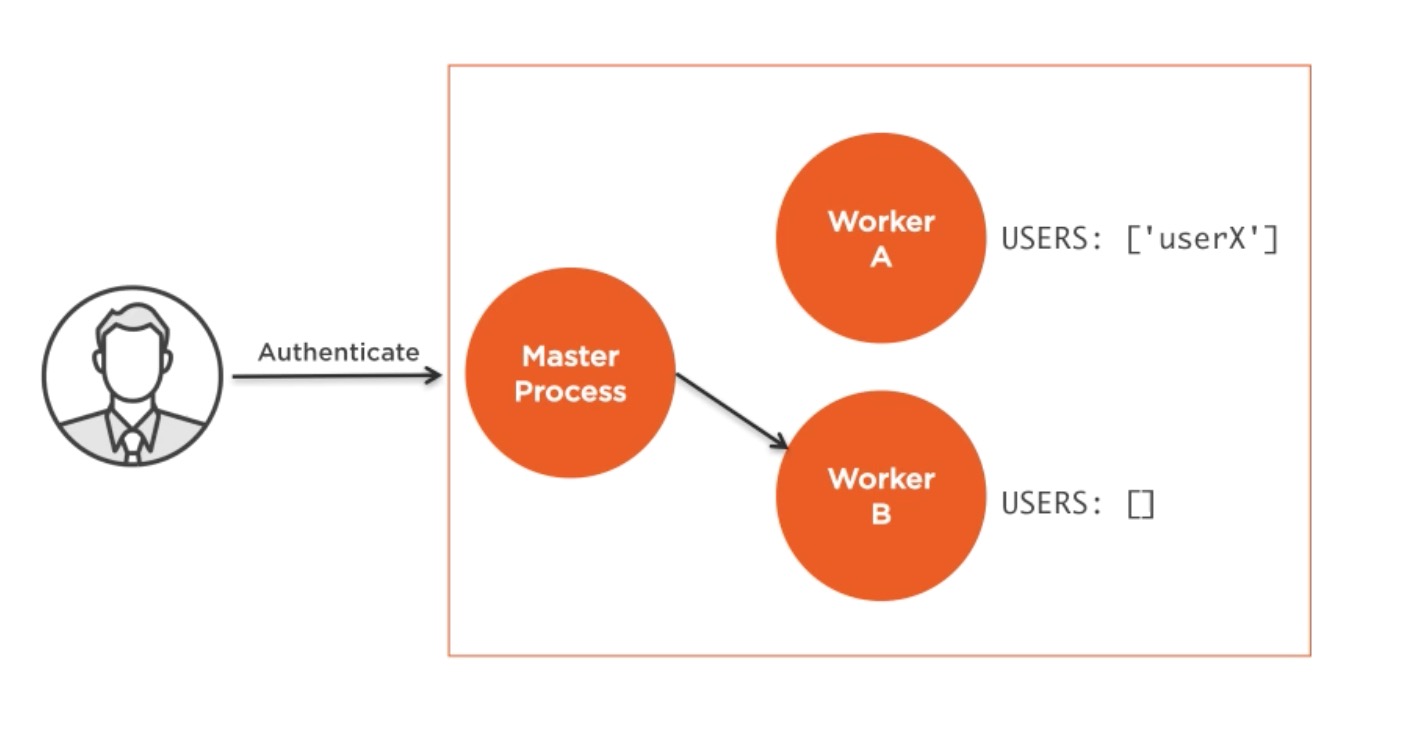
通过把这些会话信息存储在一个共享的数据库或者Redis节点,我们可以简单地在这些worker进程中共享状态,但是应用这个方法需要改变一些代码,并且有时不是很好的选择。如果你想达到共享会话而不能动你的代码时,这个具有较少的侵略性,但不是很有效率,你可以使用众所周知的粘性负载均衡。
这个很容易实现,因为有很多负载均衡实现者都支持这个策略。思想也很简单,当一个worker实例验证了用户,我们把认证记录保存在负载均衡层。然后,当同一个用户发送一个新的请求时,我们在这个记录里做一次查询,找到哪个服务有认证的会话信息,然后将请求发到那个服务上,而不是让主线程重新分配一个。这种方式下,server的代码不用改变,但是我们对用户认证也没有从负载均衡处获得好处,所以如果你没有其他选择,那就仅用粘性负载均衡吧。cluster模块不支持粘性负载均衡。但是其他负载均衡者可以被配置来实现。